Video Coding for Machines: A Paradigm of Collaborative Compression and Intelligent Analytics
Abstract
Video coding, which targets to compress and reconstruct the whole frame, and feature compression, which only preserves and transmits the most critical information, stand at two ends of the scale. That is, one is with compactness and efficiency to serve for machine vision, and the other is with full fidelity, bowing to human perception. The recent endeavors in imminent trends of video compression, e.g. deep learning based coding tools and end-to-end image/video coding, and MPEG-7 compact feature descriptor standards, i.e. Compact Descriptors for Visual Search and Compact Descriptors for Video Analysis, promote the sustainable and fast development in their own directions, respectively. In this paper, thanks to booming AI technology, e.g. prediction and generation models, we carry out exploration in the new area, Video Coding for Machines (VCM), arising from the emerging MPEG standardization efforts1. Towards collaborative compression and intelligent analytics, VCM attempts to bridge the gap between feature coding for machine vision and video coding for human vision. Aligning with the rising Analyze then Compress instance Digital Retina, the definition, formulation, and paradigm of VCM are given first. Meanwhile, we systematically review state-of-the-art techniques in video compression and feature compression from the unique perspective of MPEG standardization, which provides the academic and industrial evidence to realize the collaborative compression of video and feature streams in a broad range of AI applications. Finally, we come up with potential VCM solutions, and the preliminary results have demonstrated the performance and efficiency gains. Further direction is discussed as well.




Fig. 1. Video reconstruction results of different methods.

Fig. 2. Example frames of different compression methods.
Deep Intermediate Feature Compression
1) Intermediate Feature Compression for Different Tasks
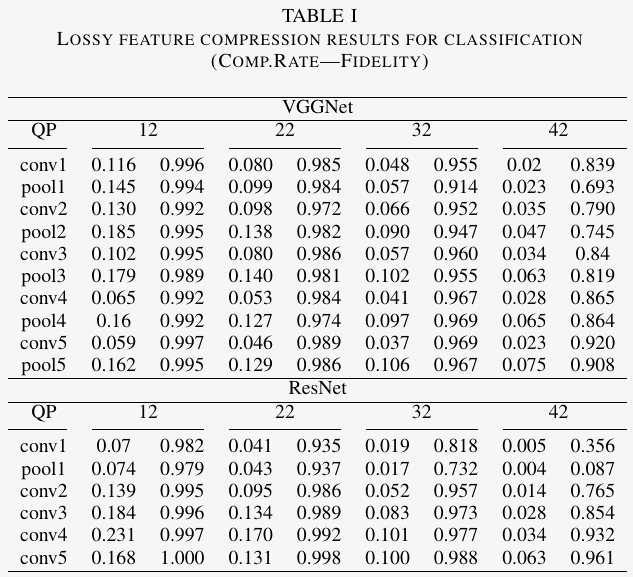
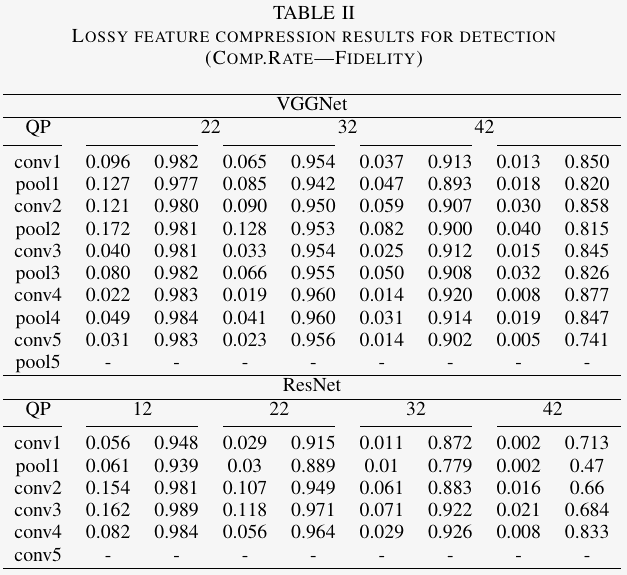
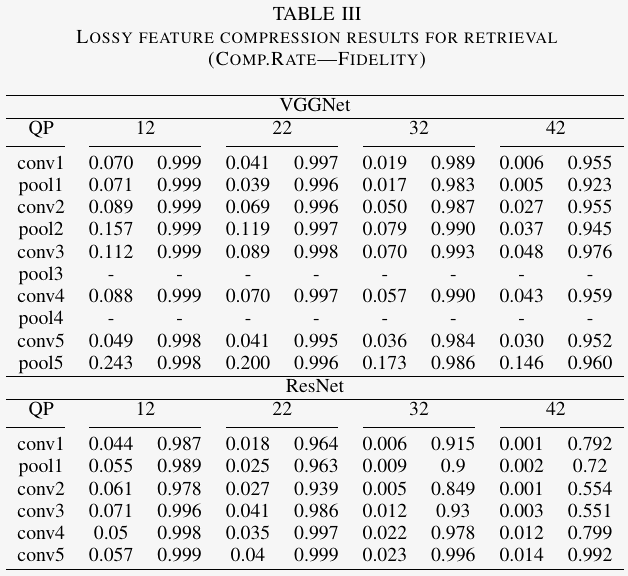
We compare the performance of compressing the intermediate features for different tasks. The results are shown in Tables I-III. The compression rate is inferred with the volume of original intermediate deep features and the corresponding bit-streams. As to the fidelity evaluation, the reconstructed features are passed to their birth-layer of the corresponding neural network to infer the network outputs, which will be compared with pristine outputs to evaluate the information loss of the lossy compression methods. More details to calculate these two metrics can be found in [107].
2) Channel Packaging
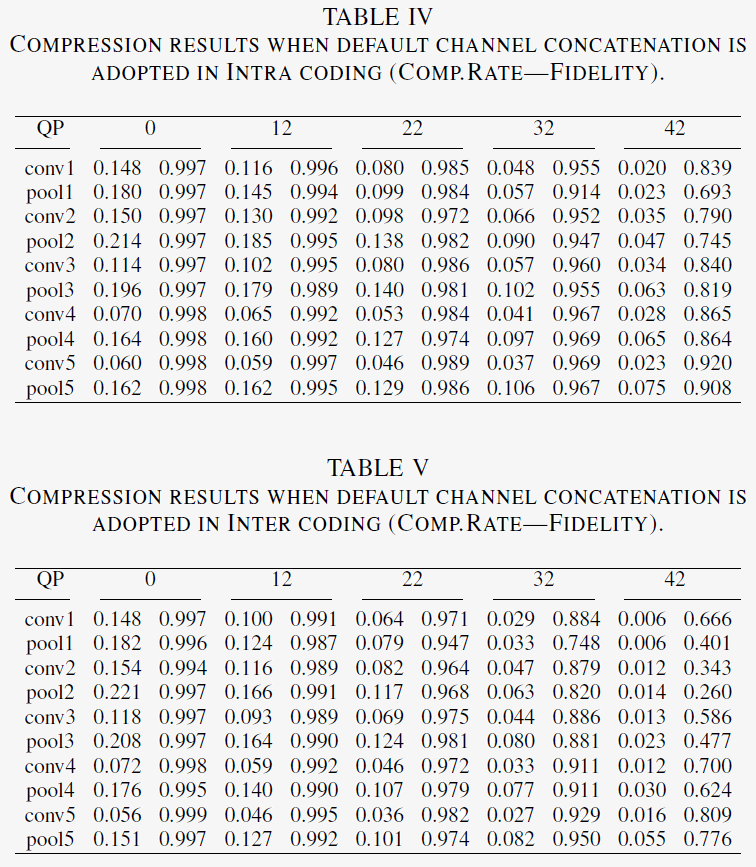
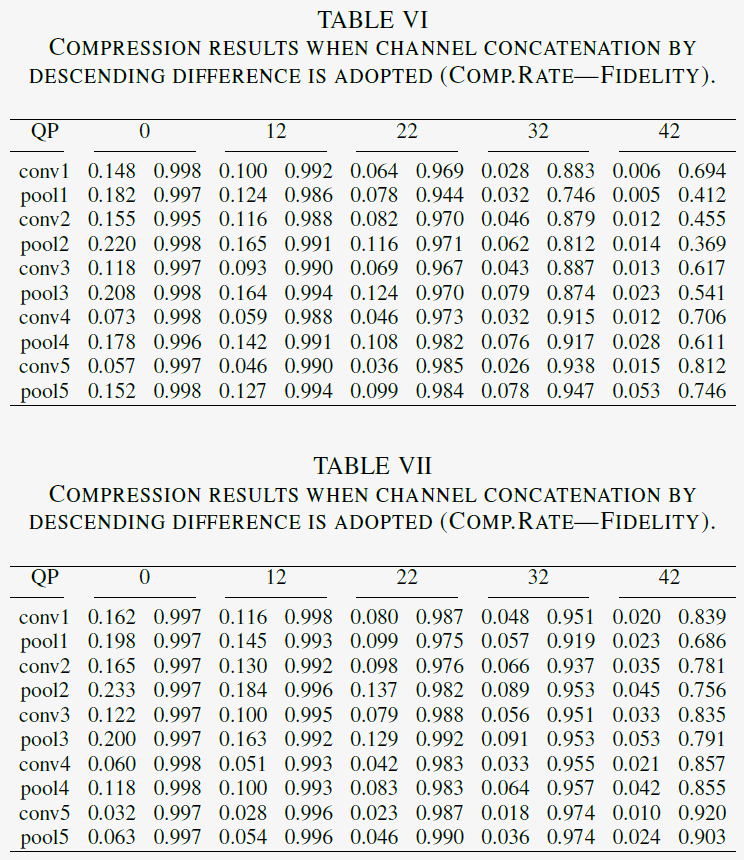
Deep features have multiple channels. It needs to decide how to arrange these features into single-channel or three-channel maps and then compress them with the existing video codecs. Three modes are provided: default channel concatenation,channel concatenation by descending difference, and channel tiling. The results by the three ways to package the channel are presented in Table IV-VI.
Joint Compression of Feature and Video
1) Quatative Results
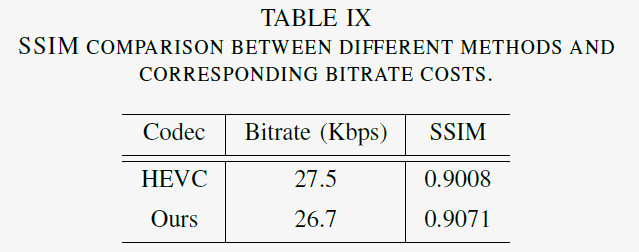
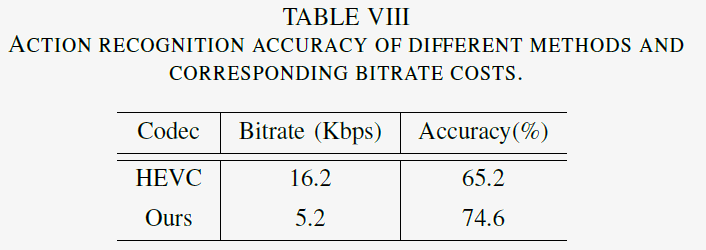
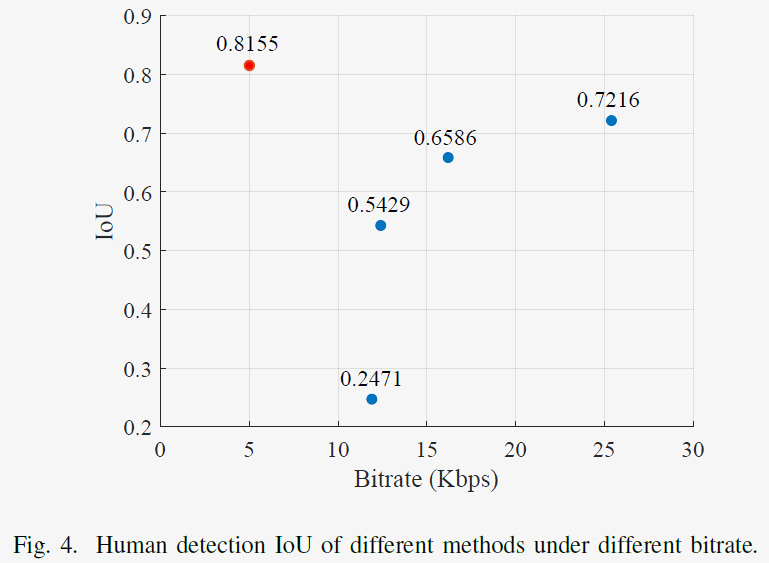
2) Human Detection

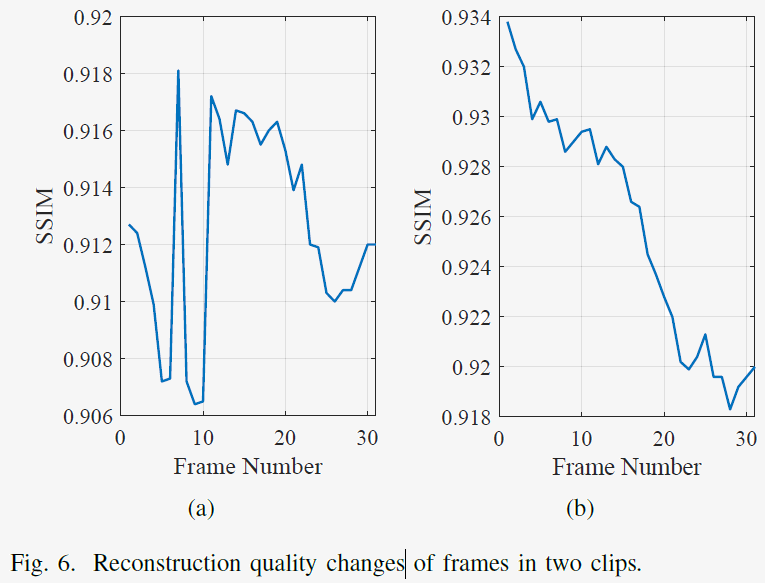
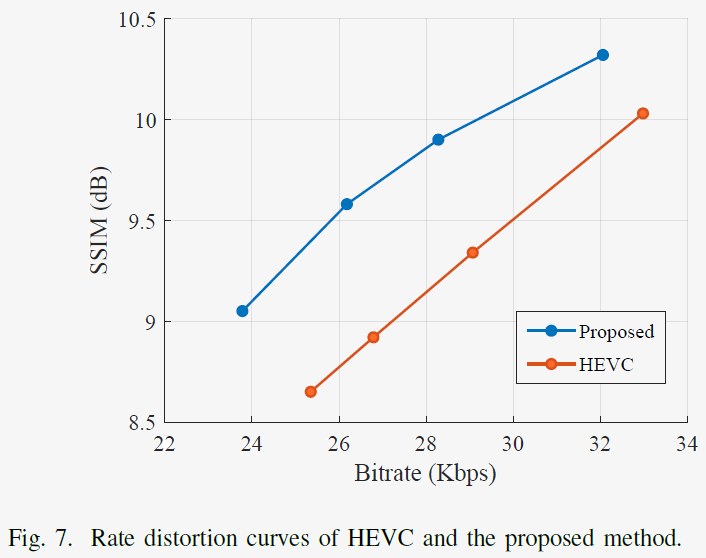
3) Reconstruction Quality Changes & RD-Curve
Reference
[107] Z. Chen, K. Fan, S. Wang, L.-Y. Duan, W. Lin, and A. Kot, "Lossy intermediate deep learning feature compression and evaluation," in ACM MM, 2019.